The AscentKB v1.0.0
that contains 8.9M commonsense assertions
is available in
🤗Datasets
with two configurations:
canonical and open, which
consist of canonicalized assertions
(see below for explanations)
and open assertions, respectively.
This KB is ~19 times larger than ConceptNet (note that in this comparison, non-commonsense knowledge in ConceptNet such as lexical relations is excluded).
More information available on the HuggingFace Hub.
Example usage:
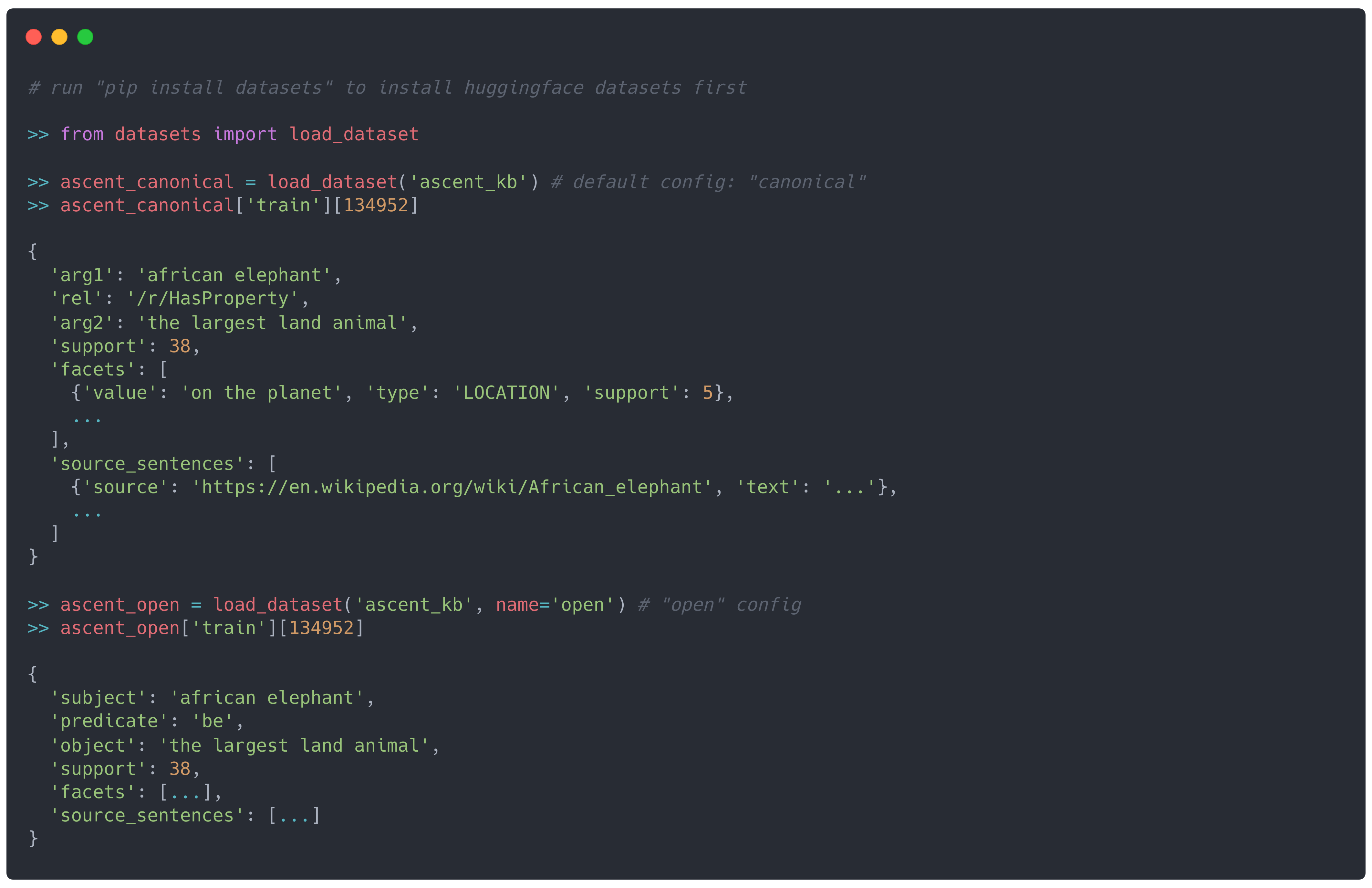
Relation canonicalization
In AscentKB v1.0.0, besides the open assertions (as in the Browse functionality), we also mapped each assertion into a canonical relation. Those relations are mostly based on the set of ConceptNet 5 relations with slight modifications:- Introducing 2 new relations: /r/HasSubgroup, /r/HasAspect (derived directly from Ascent data model).
- All /r/HasA relations were replaced with /r/HasAspect. This is motivated by the ATOMIC-2020 schema, although they grouped all /r/HasA and /r/HasProperty into /r/HasProperty.
- The /r/UsedFor relation was replaced with /r/ObjectUse which is broader (could be either "used for", "used in", or "used as", ect.). This is also taken from ATOMIC-2020.